Motivation
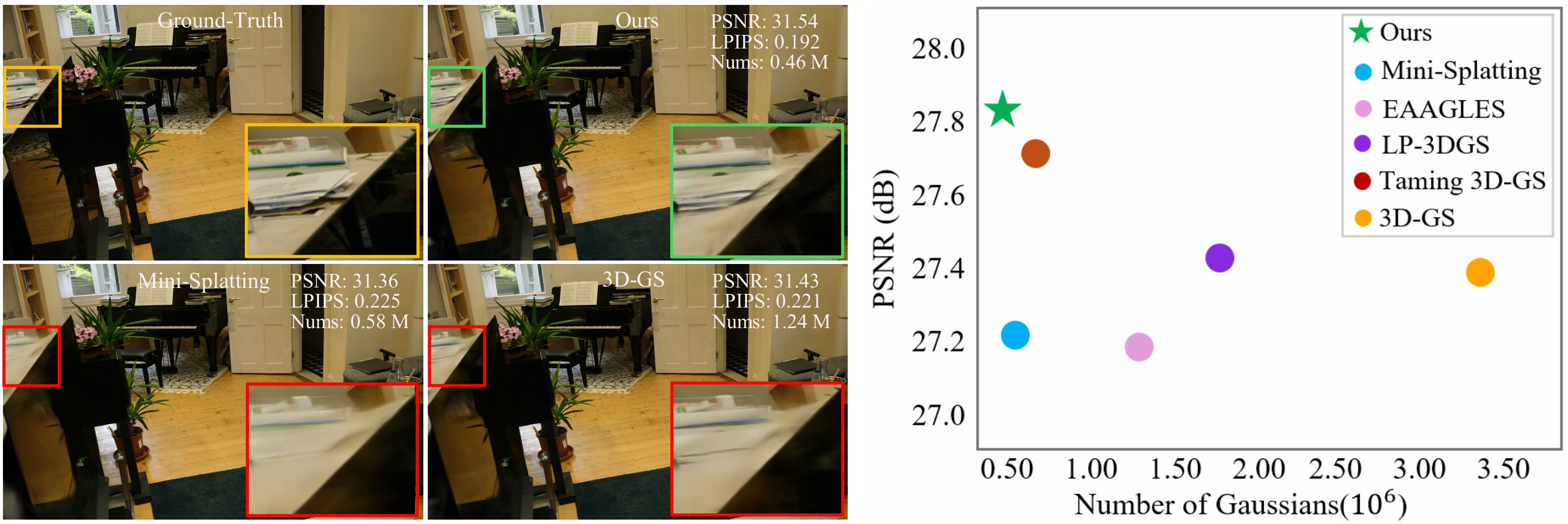
3DGS necessitates a large number of 3D Gaussians to ensure high-fidelity image rendering, particularly in the presence of complex scenes. This limits their applicability on platforms and devices with constrained computational resources and limited memory capacity. On the other hand, knowledge distillation (KD) has proven highly effective for model compression. We employ KD to transfer knowledge from various teacher models with more Gaussians into a student model with fewer Gaussians, thereby reducing the total number of Gaussians in the scene representation.
Demo
Method
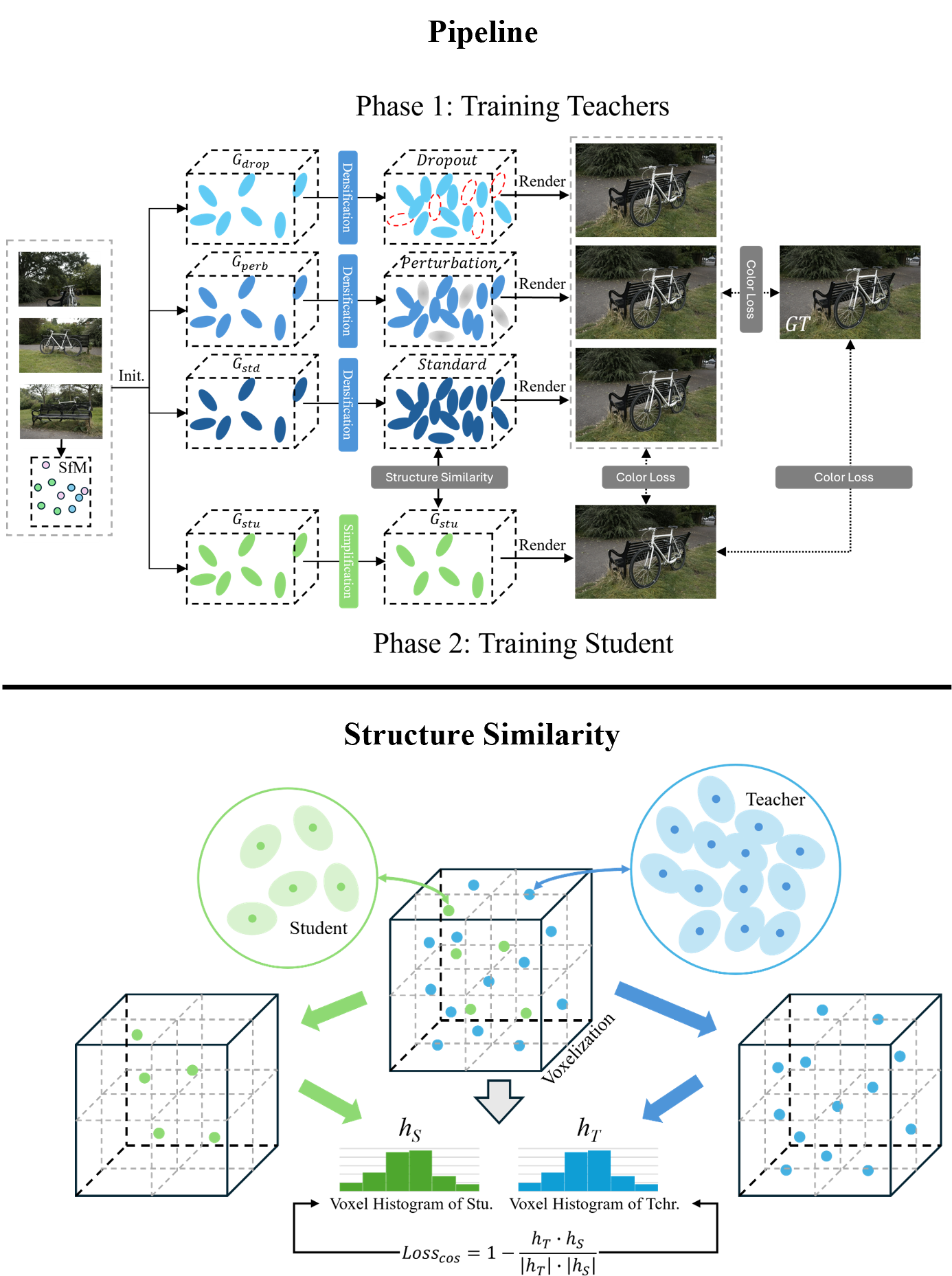
Multi-teacher knowledge distillation framework of Distilled-3DGS consists of two stages. First, a standard teacher model Gstd is trained, along with two variants: Gperb with random perturbation and Gdrop with random dropout. Then, a pruned student model Gstd is supervised by the outputs of these teachers. Additionally, a spatial distribution distillation strategy is introduced to help the student learn structural patterns from the teachers.
Citation
@article{Xiang2025Distilled3DGaussianSplatting,
title={Distilled-3DGS: Distilled 3D Gaussian Splatting},
author={Lintao Xiang and Xinkai Chen and Jianhuang Lai and Guangcong Wang},
journal={arxiv},
year={2025}}